
Attenzione!
Le parole scritte in rosso devono essere sostituite dai vostri parametri.
Beta!
Stiamo lavorando al sito e commetteremo tanti errori: potete segnalarceli tramite il modulo "Contattaci" (@giubbe.org).
Segnalateci anche eventuali vostre richieste.
Grazie. !!!
Espressioni Regolari
è una applicazione molto utile nella ricerca di espressioni (cosiddetti pattern) all'interno di files.
Come input, viene dato a grep una stringa di testo, oppure una espressione regolare da ricercare all'interno del file.
E grep restituisce, come output, la stampa a video della o delle righe che contengono la stringa o l'espressione ricercata.
Grep viene molto usato nella ricerca di parola all'interno di testi, ma anche nella ricerca sia di parole, o, meglio dire, strighe, all'interno di file di log, per poter, eventualmente, prendere in considerazioni, eventuali azioni di protezione
Una espressione regolare (in inglese regular expression, abbreviato in regex) è una sequenza di simboli, caratteri, numeri, da cui ricavare un valore booleano, vero o falso, sulla presenza del pattern all'interno del file.
Le espressioni regolari sono molto utilizzate nell'ambiente informatico. Ad esempio, il linguaggio Perl ne ha fatto uno standard, con le librerie PCRE (Perl Compatible Regular Expressions), usate tra l'altro da Apache, PHP, Postfix, Apple Safari.
Perciò, riuscire a comprendere ed a usare le espressioni regolari per una ricerca efficiente nei file è parte del sapere informatico.
Ed è per questi motivi che è fondamentale comprendere l'uso dell'applicazione di Stampa di Espressioni Regolari Globali: Grep
Useremo il file "Copyright" di Apache come cavia per effettuare le nostre ricerche di espressioni regolari.
Copiamolo all'interno della nostra cartella /home :

Partiamo con la ricerca basilare di grep, quella di una stringa di caratteri.
Anche se la stringa equivale ad una parola composta, è meglio chiamarla stringa di caratteri, perchè è così che grep la vede.
Le virgolette ( "xxx" ) servono a trovare la corrispondenza esatta del pattern nel file:

Digitiamo lo stesso comando, ma con la A di apache, stavolta, in minuscolo:

Il risultato è diverso, il che ci informa che grep distingue tra lettere minuscole e maiuscole.
Digitiamo lo stesso comando, ma con una opzione, -i :

Capiamo. che la -i sta per ignora maiuscolo o minuscolo.
Per conoscere il numero corrispondente della riga del file, molto utile in caso di ricerca in file lunghissimi, usiamo l'opzione -n :
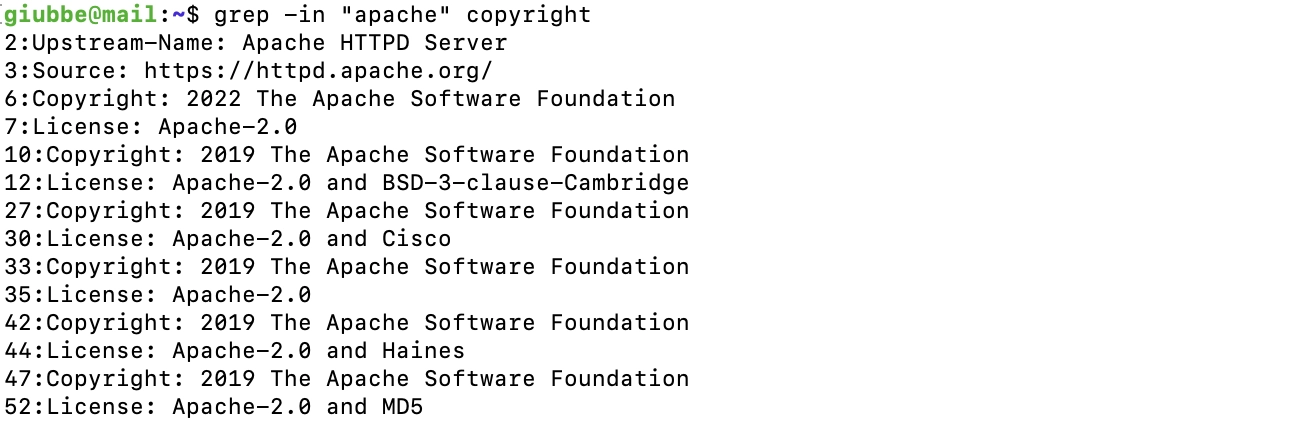
Se vogliamo trovare le righe dove la stringa non risulta, non trova riscontro, dobbiamo usare l'opzione -v :

Anche se non sembra, ma siamo già nelle espressioni regolari, cioè stringhe formate da caratteri, simboli o numeri, come lo sono a, p, a, c, h, e.
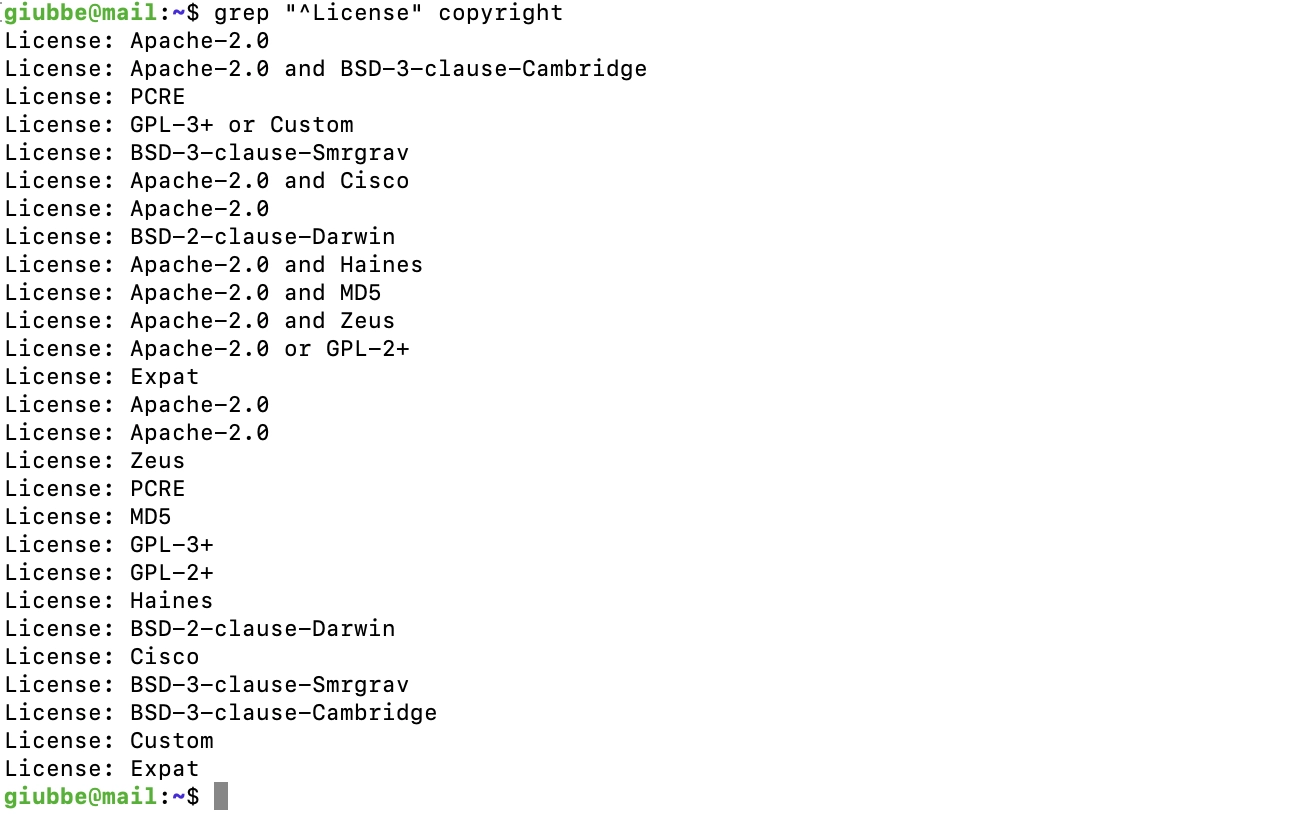
E se vogliamo trovare tutte le righe dove la stringa risulta all'inizio del rigo? Dobbiamo usare l'opzione, anzi l'ancora ^ , da porre nella stringa:
All'interno di una classe di caratteri, rappresentata da parentesi quadre ([ ]), il meta-carattere ^ nega ciò indicato dopo, cioè c'è corrispondenza se il o i caratteri dopo ^ non sono presenti nel rigo. Ad esempio [^0-9] corrisponde a tutti i caratteri fuorchè ad un numero da 0 a 9.
Cerchiamo nel nostro file corrispondenze al set di caratteri age, ma che non abbiamo s nel loro set :

Se vogliamo che la stringa si trovi, stavolta, alla fine della riga, aggiungiamo $ (dollaro) alla fine della stringa, cioè $ rappresenta l'ancora alla fine della riga.
Un uso comune è la ricerca di file che finisca con un suffisso specifico, come .txt .
Cerchiamo le occorrenze dove il rigo finisce con copyright :

Poi, abbiamo il metacarattere . (punto) che rappresenta qualsiasi carattere singolo, quindi lettera, numero, simbolo e spazio vuoto
L'unico non usabile è il carattere di nuovo rigo.
Ad esempio "a.c" corrisponde a "abc, ma anche a "a3c", oppure a "a c" e tante altre combinazioni.
Potremmo definire . il carattere jolly.
Ricerchiamo tutto ciò con almeno 2 caratteri seguiti da age :

Torniamo alle parentesi quadre [ ] , classe di caratteri.
Permettono di cercare uno qualsiasi dei caratteri inseriti al loro interno.
Cercheremo stringhe che hanno re ed anche [ p oppure t ] , subito dopo:

Le parentesi quadre sono molto utili anche per indicare un' intervallo di caratteri.
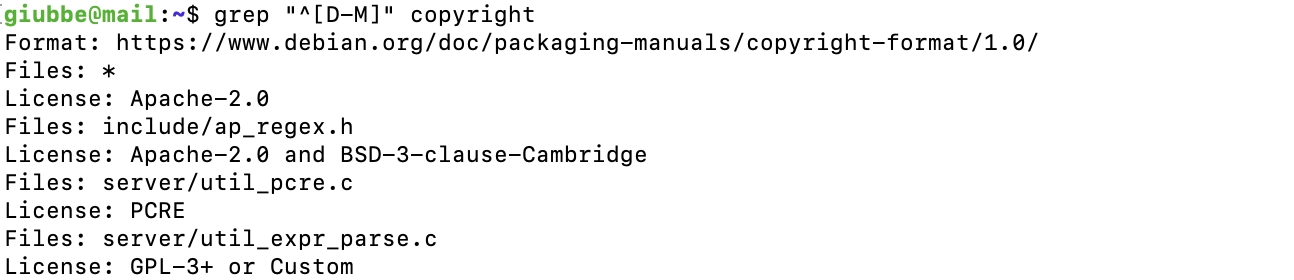
Ad esempio, se vogliamo trovare tutte le occorrenze dove il rigo inizia con un carattere maiuscolo tra D e M, indichiamo :
Altri esempi molto usati in ricerche :
[a-zA-Z0-9] corrisponde a qualsiasi lettera minuscola o maiuscola oppure a qualsiasi cifra.
[^abc] unito all'accento circonflesso, invertendo il significato, corrisponde a qualsiasi carattere eccetto "a", "b", o "c" .
Sempre all'interno delle parentesi quadre possiamo inserire caratteri POSIX. Spesso, nelle ricerche informatiche, ci imbattiamo in questi; perciò, è bene almeno conoscerne la valenza :
[[:alnum:]] corrisponde a qualsiasi carattere alfanumerico ;
[[:alpha:]] indica qualsiasi carattere alfabetico, lettere ;
[[:blank:]] indica spazi e tabulazioni ;
[[:cntrl:]] indica caratteri di controllo ;
[[:digit:]] corrisponde a qualsiasi cifra decimale ;
[[:graph:]] indica caratteri grafici (visibili) ;
[[:lower:]] si riferisce a lettere minuscole ;
[[:print:]] indica caratteri stampabili, compresi gli spazi ;
[[:punct:]] corrisponde ai caratteri di punteggiatura ;
[[:space:]] indica caratteri di spazio ;
[[:upper:]] indica lettere maiuscole ;
[[:xdigit:]] indica le cifre esadecimali.
Il metacarattere più usato nelle ricerche è * (asterisco); indica di ripetere i caratteri prima di esso per zero o più volte.
Ad esempio, a* corrisponde a nessuna occorrenza, oppure a più occorrenza della lettera a : " ", "a", "aa", "aaa" .
.* corrisponde a zero o più caratteri di quasiasi tipo. Molto usato nella ricarca di stringhe.
[abc]* corrisponde a zero o più occorrenze dei caratteri "a", "b" o "c" .
Adesso, cercheremo, nel nostro file, stringhe con all'inizio la lettera R maiuscola, con altre lettere o spazi al suo interno e con la lettera s finale.
s finale non vuol dire che la parola deve finire con la s, ma che la ricerca finisce alla corrispondenza della s :

Nelle espressioni regolari, il metacarattere + indica una o più occorrenze del carattere (o gruppo di caratteri) che lo precede. Egli specifica che il carattere precedente deve apparire almeno una volta e può ripetersi infinite volte.
Ad esempio, a+ corrisponde a "a", "aa", "aaa", etc.
[0-9]+ corrisponde a "1", "12", "123" e così via.
A differenza di * (asterisco), + deve avere una occorrenza; ad esempio a+ non corrisponde mai a " ".
Proviamo a cercare le occorrenze di [0-9]+ :

Le parentesi tonde ( ) vengono utilizzate per ragruppare sequenze di caratteri da trattare come unica entità.
Ad esempio, (abc)+ corrisponde ad "abc" ripetuto anche alcune volte {"abcabcabc").
Senza le parentesi tonde, abc+ corrisponde ad ab seguito da almeno una c ("abc"), ma anche da più c ("abcccccccc").
Per utilizzare le parentesi tonde con grep e non dargli il valore di "(" cioè letterale di parentesi, dobbiamo aggiungere una barra rovesciata ( \ ) davanti alla parentesi.

Lo stesso enunciato, ma senza gli "backslash", produce :

Perchè ha cercato le occorrenze di " (list) " e non di " list ".
Usiamo lo stesso procedimento, se vogliamo che il punto non rappresenti un carattere qualsiasi, ma un punto. Dobbiamo anteporre la barra rovesciata ( \ ) davanti al punto . (punto)
Per cercare tutte le stringhe che iniziano (^) con lettere dalla A alla Z maiuscole ( [A-Z] ), con altri caratteri all'interno della stringa ( .* ) e che finiscano con il punto ( \.$ ), digitiamo:

Abbiamo anche altri esempi di Espressioni Regolari Estese, evoluzioni delle espressioni regolari di base, viste finora e che offrono funzionalità aggiuntive.
Ad esempio, non necessitano della barra rovesciata davanti ai caratteri speciali.
Abbiamo già incontrato le parentesi tonde .
Ad esempio, per ricercare (insieme) in un testo, come espressione regolare di base usiamo le barre rovesciate per usare la parentesi per il suo uso come carattere:
Nelle espressioni regolari estese, diventa semplicemente:
L'operatore | , (barra dritta), chiamato "pipe" oppure "or", nelle espressioni regolari, permette di specificare più alternative.
Cioè, indica di cercare una qualsiasi corrispondenza dei pattern separati dal simbolo " | " .
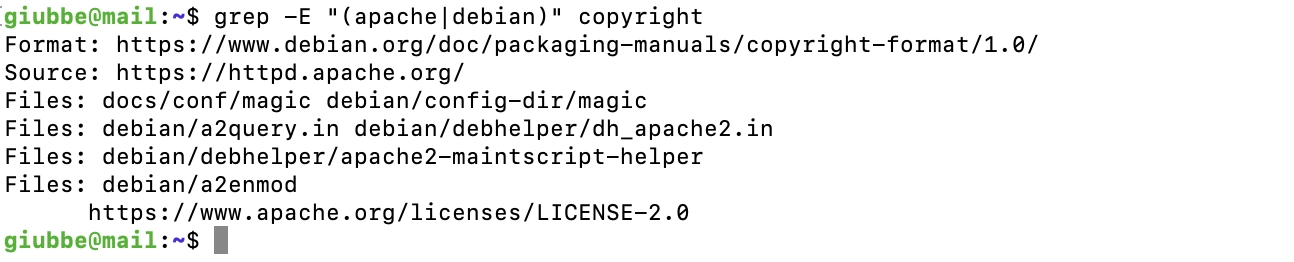
Per ricercare una stringa (apache) oppure un'altra (debian) in alternativa ( | ), digitiamo :
Possiamo usare il metacarattere ? (punto interrogativo) , il quale indica che il carattere (o il gruppo di caratteri) che lo precede può comparire zero o una volta nell'occorrenza. Cioè, rende opzionale l'elemento che lo precede.
Ad esempio, "colou?r", corrisponde sia a "colour", sia a "color" ; "ab?c" corrisponde sia a "ac", sia a "abc".

Le parentesi graffe {} sono utilizzate per specificare la quantità di ripetizioni di un carattere o di un gruppo di caratteri, che lo precedono.
Si usano le parentesi graffe sia per indicare un numero esatto, sia un intervallo minimo-massimo, oppure per indicare un numero minimo di ripetizioni ;
Ad esempio, a{4} corrisponde esattamente a 4a (aaaa);
[0-9] {2,3} indica un numero compreso tra due e tre cifre ;
[xyz]{3,} corrisponde a tre o più occorrenze di "x" , "y" o "z" ("xxx", "yyyy", "zzzzzzzzz", etc.)
Adesso useremo i meta-caratteri {} per trovare le ripetizioni di 3 vocali minuscole nel file :

Per trovare stringhe lunghe da 15 a 18 caratteri, digitiamo : :

Per finire, vogliamo nominare alcune abbreviazioni comuni nelle espressioni regolari, magari già affrontate, ma qui raggruppate, che si ritrovano spesso quando ci imbattiamo in algoritmi di ricerca :
\w è l'abbreviazione di [a-zA-Z0-9], cioè qualsiasi carattere alfanumerico ;
\W è l'abbreviazione di [^a-zA-Z0-9], cioè qualsiasi carattere non alfanumerico ;
\d abbrevia [0-9], qualsiasi cifra tra 0 e 9
\s indica uno spazio bianco (spazio, tabulazione) ;
\S indica un carattere non di spazio ;
\b indica il confine di una parola (inizio o fine) ;
\B indica al contrario un non-confine di parola ;
. corrisponde a qualsiasi carattere, se non quello "a capo" ;
* corrisponde a zero o più occorrenze ;
+ corrisponde ad una o più occorrenze del carattere o gruppo precedente ;
^ corrisponde all'inizio della stringa ;
$ corrisponde alla fine della stringa ;
Ad esempio, per cercare tutte le occorrenze di "com" digitiamo:

Conoscere le espressioni regolari è fondamentale per parlare il linguaggio informatico; ad esempio, per implementare restrizioni negli header e body di Postfix, per creare filtri in Fail2ban, magari per poterci fare anche un motore di ricerca.